I humbly set a thought upon the world
Of many hundred words that men have heard.
At the Recurse Center, I modified a Shakespeare language generation model to output lines in iambic pentameter. Since meter is such a distinct trait of Shakespeare’s writing and a relatively mechanical part of language, I wanted to see if you could model it with a language generation program.
To quickly illustrate what I mean by meter, let’s look at “Twinkle, Twinkle, Little Star.” Below, I’ve bolded the syllables you would naturally tend to stress if you read them aloud.
(Twink)le, (twink)le, (litt)le (star)
(How) I (won)der (what) you (are)
That extremely regular pattern of emphasis is the lyric’s meter. The pattern of having every other syllable stressed is called iambic. Pentameter means having five stresses per line. Thus, Shakespearean lines tend to scan like this:
Shall (I) com(pare) thee (to) a (summ)er’s (day)
Thou (art) more (love)ly (and) more (temp)e(rate)
Recurrent Neural Networks (RNNs) have been for popular language generation in the last few years. They’re more capable than markov chains and simpler than a transformers. Andrej Karpathy’s influential blog post, “The Unreasonable Effectiveness of Recurrent Neural Networks” includes some Shakespeare pastiche generated with an RNN as an impressive example:
PANDARUS: Alas, I think he shall be come approached and the day When little srain would be attain'd into being never fed,
His model does a good job of imitating play formatting and Shakespeare’s vocabulary, but doesn’t do a great job of recapitulating iambic pentameter. The output is often iambic, but the line breaks come after varying numbers of syllables, and you can’t make it write in meter consistently. (Also of course it doesn’t actually make sense.)
My approach
I decided to also use an RNN as my language model. Rather than embedding metrical information into the training data, my approach was just to train a word-level RNN on the plain text and then constrain the output so that it could only ever choose words that followed iambic pentameter.
The RNN generates text by predicting one new word at a time based on the words that have come before it. At each step, the model gives you a vector representing how likely it thinks each word in the vocabulary is to come next. If you feed it, “The king will…” it suggests “have”, “bid”, and “speak” as very likely to come next and “nest”, “straw”, and “lightness” as very unlikely. (And another 9,994 words as somewhere in between.)
My plan was to take the probability vector of those 10,000 words and multiply it by another vector that modeled how well each word fit the meter at that position in the line. e.g., if you have “(Twink)le, (twink)le…” you know that “(litt)le” and “(tin)y” fit the line better than “pe(tite)“.
If we give the Shakespeare model “Again we come…”, it suggests “to” and “home” as pretty likely next words. However, “A(gain) we (come) to…” fits the meter better than “A(gain) we (come) (home)…”, so the model should reduce how highly it rates “home.” Doing this process on the entire vocabulary, you can cull all of the suggestions that don’t fit in the meter. Below is an illustration of how my model weights likely words according to meaning (RNN) and meter.
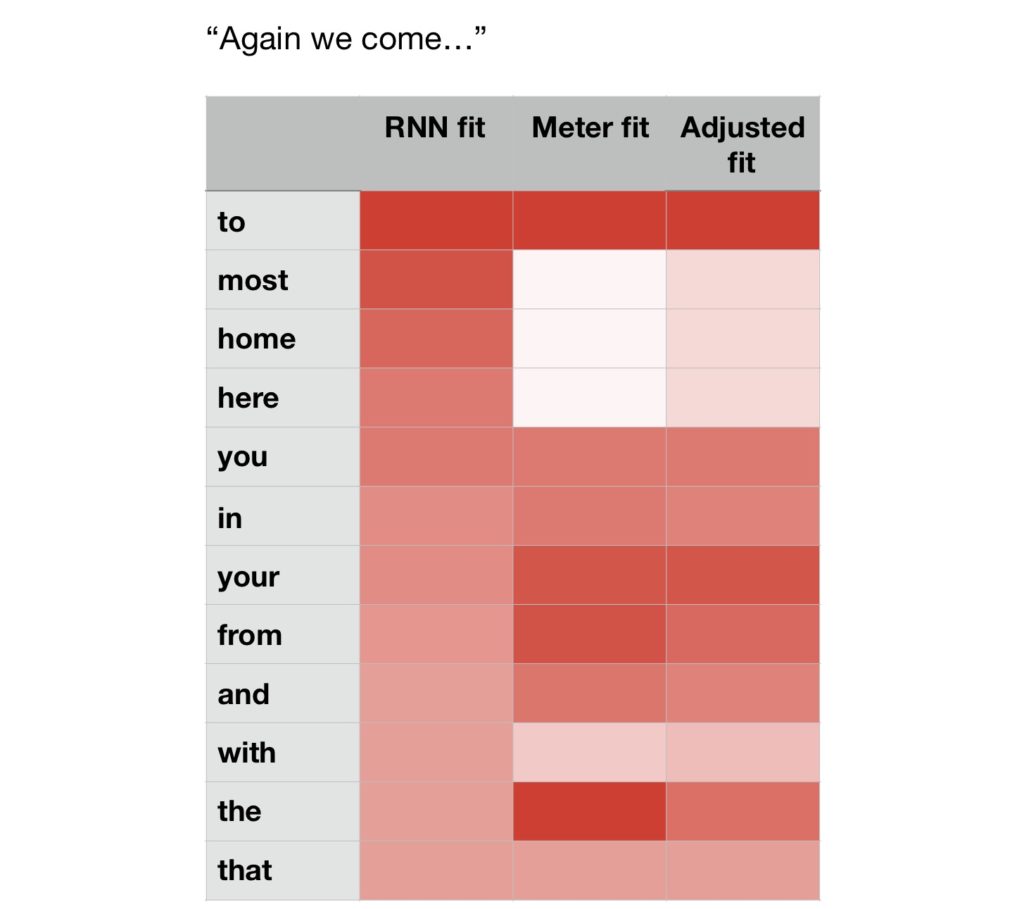
The reason the meter scores aren’t binary is that I wanted to account for the fact that words aren’t always emphasized in only one way. I ran Shakespeare’s plays through a text-to-speech algorithm and recorded how often different words received different stresses to try to estimate their probabilities of fitting into a particular place in a line. A better solution would be to judge from the actual context of the input line, but I didn’t get there.
Results
If you let the model run, it keeps rigidly in iambic meter! Although, again it usually doesn’t make sense.
Your (ans)wer, (Tit)us; (mark) the (word), for (no)
Of(fence). I (tell) your (daug)hter (won)der (old)
My (grac)ious (lord) - that (know) is (mad) for (now)
But (where)fore (breathe) our (ar)my? (Go) the (ways)
My lord the husband bid the end to came
His ransom. O my heart away and truth
And shallow things that all shall not betray
Adding interactivity
I was more interested in making a creative tool that a human could interact with than a pure computer model, so I created a small UI for the modified RNN. Using it, a person can write lines in meter by choosing from the model’s suggestions at every word.

Here are some Shakespearean lines I had fun writing with the UI:
Shall I compare thee to a secret place?
Your name is much of late in heaven known
But only now the world doth mind your face
And dream of speech together in your crown.
Alas, my lady Anne is mad for love;
But Heaven hide this guilt from John of York.
He loves me better than his heart did think
it fit to tell. But now he wrongs my state
and sends an army here to crown his son.
I dare to speak again of Henry's death.
Now villain look you here, I prithee see
Thy conscience says thou art an empty dog
And yet thou wilt needs praise me as a lord
Till Edward fall and rest the heavy thought
Upon his grave.
Sounds Shakespeare-y! Makes a little bit of sense! The rhymes in that first one I just got lucky with after trying a few different things. (But I also worked on working towards a rhyme with an RNN at RC!)
Part of speech
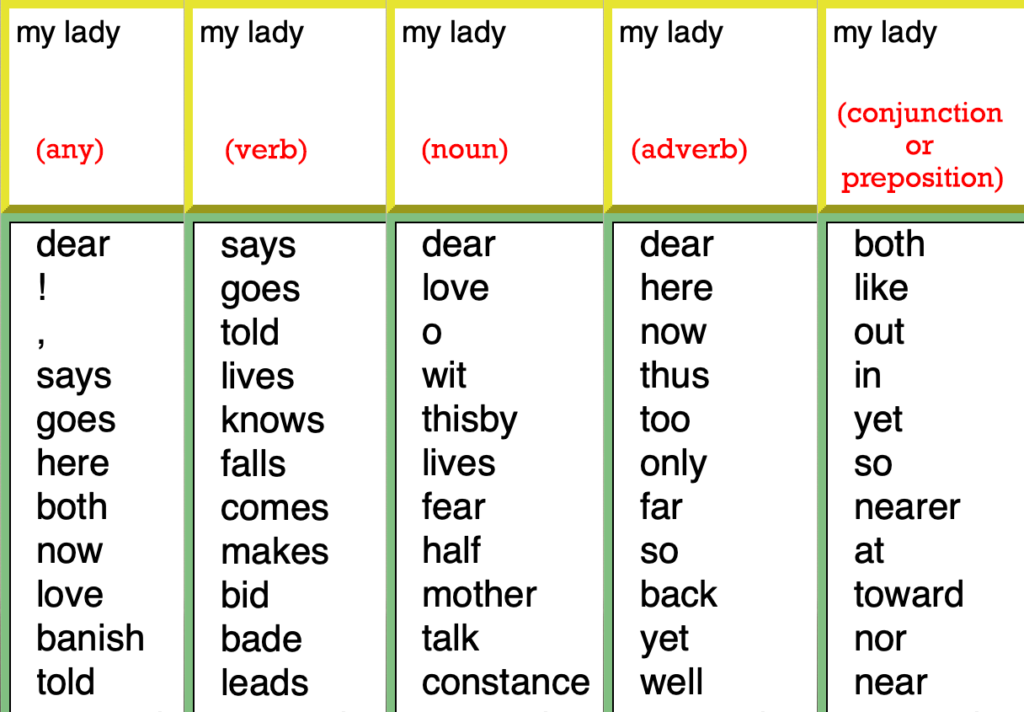
The next piece of interactivity I wanted to add was part-of-speech restriction. My experience using RNN language models is that very often you get written into a corner where none their top options could possibly continue an English sentence. So, in the same way I restricted the output by meter, I added the ability to restrict the output by part of speech. Below you can see the best suggestions for continuing the line “My lady…” given different part of speech restrictions.
Last thoughts
Overall, the model is way too rigid with its meter. Neither Shakespeare nor any poet ever wrote this way without a syllable out of place, because it’s too inflexible and monotonous. So it would be smart to allow some suggestions to fit imperfectly. There is also still a lot of tweaking I could do on how meter is weighted against meaning and how to handle words whose pronunciation varies.
Thinking in Shakespearean language and especially meter is very hard. I thought this project was a fun way to be able to improvise a little in that voice and easily generate lines you couldn’t have written yourself. I think explicitly modeling meter is an interesting idea as people get more interested in using language generation for poetry. Meter isn’t so straightforward a computer can handle it perfectly, but it’s certainly a lot more mechanical than meaning!