During my batch at the Recurse Center, I deployed an interactive tool finding puns. (Defined by me as words that share some noticeable common sounds.) Users can search two different categories of words and look through the results for words that pun or sound poetic together. Searching for colors and cars can yield amber / Lamborghini or khaki / Cadillac, searching for names and sea creatures can yield Carol / coral or Steven / sturgeon.
The program’s steps are:
- Pull two big lists of synonyms based on the user’s input. (Using word2vec to generate related words.)
- Find the words from those two lists that sound the most alike. (Using a phonetic vectorization algorithm I came up with.)
Here’s what it looks like searching for adjectives like “beautiful” and landscape features. The left and right columns have the category words, sorted by how well they fit the category; and the center columns have the punning pairs, sorted by how much they sound alike.

You can scroll through the results and click on pairs you like to print them out. You can also click on a word in the blue columns to pin it to the top and search specifically for its matches.
Try out a search of your own!
- Colors that sound like cars! (amber / Lamborghini)
- Names that sound like foods! (Karen’s Carrots)
- Countries that sound like verbs! (Peru / perused)
Domain name puns
I extended the project by making a constrained version that matches whatever category you input against a list of all the available top level domains (e.g., .com, .biz. .pizza).
So if you want to make a website about fish with a pun baked in, you can find gems like eels.deals, tuna.tunes, catfish.cash, and roe.rodeo.
You can try that tool out at puns.plus/domain!
How does it work?
If you want to see more details about how I implemented this, read on!
What determines if words have similar meanings?
I’m using Google’s word2vec for meaning match. The model thinks two words have similar meanings if they tend to show up alongside the same words. If “red” and “blue” both show up near the words “color,” “paint,” and “shade,” then the model thinks they’re similar. It was trained on news articles so it has a bias towards the kinds of sentences that show up in the news.
What determines if words sound alike?
Sound similarity uses an algorithm I wrote that based on a word’s pronunciation. It checks if two words have a lot of phonetic sounds in common, preferably in order, next to each other, and in a syllable that’s emphasized.
The algorithm was initially inspired by how FastText vectorizes the spelling of words. They take a word like “word” and break it into all of the runs of 1, 2, and 3 letters that it has: w, o, r, d, wo, or, rd, wor, ord.
It then determines that “word” is spelled most similarly to the words that share the most of those chunks.
- “wordy” is similar because they share “wor” and “ord” (and all the shorter ones).
- “worth” is similar because they share “wor”.
- “aardwolf” is kind of similar because they both share “wo” and “rd”.
- “botch” is not that similar because they only share an “o”.
To do this with pronunciation, we can take the word “forward” and break it into its phonemes (the individual sounds that make it up). According to the pronunciation key in my dictionary that’s “fôrwərd.”
In the image below, I’ve broken up “fôrwərd” into its sets of 1, 2, and 3 consecutive sounds. Below the circle showing each set, I’ve added some words that also share the sound(s).
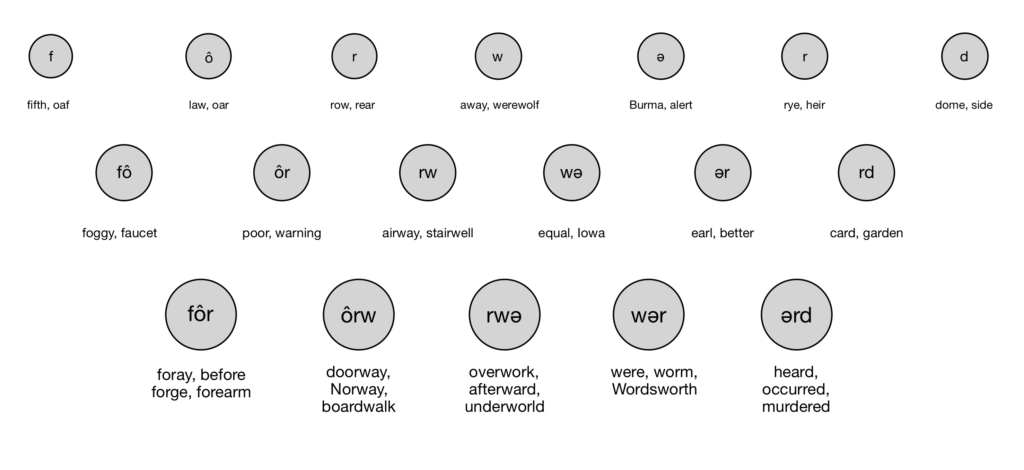
Each of these words shares some sounds in common with “forward,” and if you say the words together, you can probably hear the repetition. The words in the lower rows match longer sets of phonemes, so the overlap tends to sound stronger.
So the words with the best sound match are the pairs that share the highest percentage of their phoneme chunks (the circles above). The closest match for “forward” is “foreword,” which is a homonym. Skipping different conjugations like “forwarded”, the next best matches are ford, straightforward, afford, forewarned, word, northward, afterward, and four.
How do you do the math?
For every word, I make a vector of all of the chunks it contains, as illustrated above. The vector has one dimension for every possible chunk of 1-3 phonemes (~70,000). The values in these dimensions are 0 for every sound it doesn’t have, and then 1, 2, or 3 for every sound it does have depending on the length of the sound.
In the table below, you can see how “forward” overlaps with some other words. This is a truncated version of the matrix I use to implement the search.
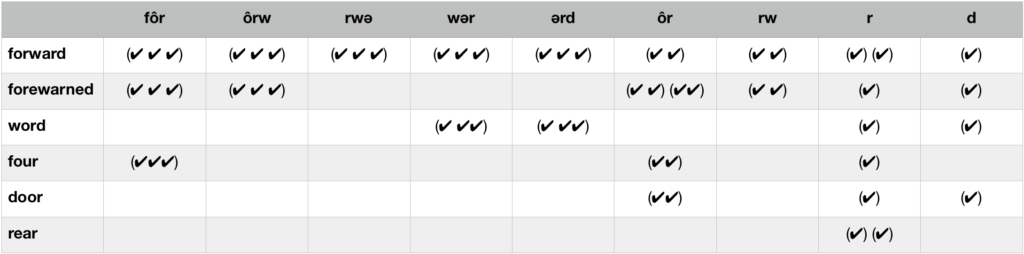
To get two words’ similarity scores, I take their cosine distance, which measures what percentage of their features are expressed in both. It’s common to use dimensionality reduction or an approximate nearest neighbors algorithm to make the math less computationally intensive. (Word2Vec, for example, reduces millions of dimensions to 300.) However, the results got worse when I tried this, and I found I really liked having the individual dimensions be legible. (i.e., If you want to bear down on just words with the “four” sound, you can just select the fôr column and get all of them right away.)
I opted instead to store my data in large sparse matrices. To make the computations faster for the web implementation, I precomputed every word’s similarity score to every other word and cached the results in a nearest neighbors matrix. This approach actually led me to accidentally create a little query language that I’m very fond of. If you want to look at Python code, here is a gist of the implementation.